如果您说“Moshi-moshi”,您几乎会立即得到自然日语的答复。 AWS 推出了一个系统,即使在汽车或智能家居设备上的互联网连接不稳定的情况下,您也能获得这种对话体验。关键在于 Amazon Nova 2 Sonic(直接从音频生成音频)和 WebRTC(低延迟通信的代名词)的结合。在本文中,我们将通过两个具体例子来解读我们的生活和交通格局将如何改变:一个是通过语音控制智能家电,另一个是人工智能在驾驶时监视驾驶员。
2026 年 5 月 13 日,AWS 宣布推出一款用于构建实时音频流应用程序的解决方案,该解决方案结合了 Amazon Nova 2 Sonic (Nova Sonic) 和 Amazon Kinesis Video Streams WebRTC。
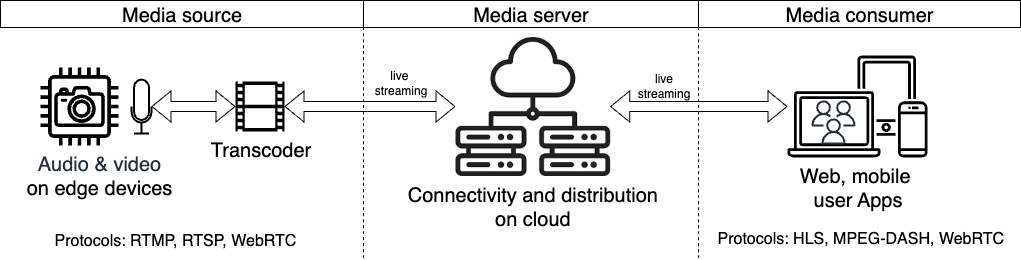
作者是黄忌函、陈冰、张拉娜和 Siva Somasundaram。 Nova Sonic 提供集成的语音到语音架构,可实现低延迟语音对话。 WebRTC 具有自适应比特率、前向纠错、抖动缓冲区管理等功能,并且与 Chrome、Firefox、Safari、Edge、Android 和 iOS 兼容。我们使用 Python 库 aiortc 进行实现,并使用 WebRTCVAD 进行语音活动检测。音频数据通过 WebRTC 连接进行传输,并进行格式调整,例如从 48kHz 重新采样到 16kHz,以及从 Int16 转换为 Float32。除了通用示例之外,GitHub 还提供了两种场景:使用 Amazon Bedrock 知识库和适用于 AWS IoT Core 的 MCP 服务器的智能家居示例,以及联网汽车示例。
从: ![]()
【编辑部评论】
乍一看,AWS 的这篇公告似乎是一篇普通的技术文章,名为《语音 AI x 流技术实施指南》。然而,作为编辑部,这是“对话式边缘AI”全面普及的里程碑我是这么看的。
传统的语音AI助手主要采用“管道法”,将语音识别、语言理解、语音合成三个模型串联起来。这种方法的缺点是每一步都会剥夺上下文信息。说话者的语调、停顿和情绪语气——这些非语言信息一旦被转录成文本就会丢失。 Nova Sonic 采用的集成架构是从结构上消除这种信息丢失本身的尝试。
这篇文章的本质新颖之处在于使用“WebRTC”而不是 WebSocket 连接 Nova Sonic 的要点虽然这两个协议看起来很相似,但它们的设计理念却完全不同。 WebSocket基于TCP,强调可靠性,而WebRTC基于UDP,强调实时性。后者在语音对话等应用中具有压倒性的优势,即使某些数据包丢失,零延迟也更好。
这里我想指出的是,组合合作伙伴是 Amazon Kinesis Video Streams WebRTC。 WebRTC本身只是一个标准,信令服务器和STUN/TURN服务器的实现是实现者的责任。通过使用 KVS WebRTC,它以托管方式提供这些,即使是初创企业也能够在没有运营基础设施负担的情况下进行全球扩张——这种“大幅降低进入壁垒”是本次公告的隐藏主角。这是编辑部所看到的。
作为具体用例呈现的两个场景也具有启发性。在智能家居示例中,Amazon Bedrock 知识库从用户模糊的指令中选取 MQTT 主题,并通过 AWS IoT Core 的 MCP 服务器与设备进行交互。诸如“让客厅变暗一点”之类的日常用语被翻译成特定于设备的命令。
另一个联网汽车示例具有技术更先进的实施方式。语音助手可以检测驾驶员危险地使用智能手机并提醒驾驶员。同时,该结构允许监控人员在独立的视频通道上查看实时视频。
一个值得注意的技术点是在服务器端实现语音活动检测(VAD)层。通过使用基于高斯混合模型的 WebRTCVAD 在将静音和噪音传递给 Nova Sonic 之前对其进行过滤,该设计减少了 Nova Sonic 处理的音频令牌的数量,从而降低了成本和延迟。这是一个在语音AI商业化运作中经常被忽视但却极其实用的想法。
从积极的一面来看,这种组合带来了广泛的可能性。支持多语言切换的对话AI将降低旅游业和国际物流中的语言障碍。在制造现场,跨国团队协作更加顺畅,它可以成为无法在医疗和护理环境中实际操作设备的人们的新界面。。
另一方面,也必须牢记潜在的风险。不断收听音频的设备连接到云端的结构需要从隐私保护和数据主权的角度进行精心设计。处理语音生物识别的监管框架,例如欧盟的人工智能法和日本的人工智能运营商指南,未来可能会变得更加严格。开发人员必须始终意识到技术上可行的内容与社会可接受的内容之间的差距。大概。
此外,联网汽车场景中显示的“驾驶员监控”虽然有助于提高安全性,但它还具有监控工人和积累行为数据的方面。根据技术的使用方式,它既可以用作福利工具,也可以用作管理工具。这种模糊性是一个应该从设计阶段就纳入考虑的问题。
从长远来看,这一公告为过去几年的行业挑战提供了答案:“在云端使用大规模人工智能,而不会在边缘设备上产生任何不适。”Nova Sonic 在东京地区推出这一事实意味着,现在已经为在日本市场实现低延迟、自然的音频体验奠定了基础。
从主张“科技促进人类进化”的innovaTopia看来,语音接口是一个将从根本上改写“人类与机器交互方式”的技术领域。继键盘、鼠标、触摸屏之后的第三次输入革命现在已经达到了可实施的程度。。我希望读者能够利用这篇文章作为了解如何与这一浪潮相关以及如何塑造未来的资源。
【术语解释】
语音到语音 (S2S)
这是一种直接从语音生成语音的处理方法,无需先将语音输入转换为文本。通过将传统的“语音识别→语言处理→语音合成”三级流程集成到单个模型中,可以实现低延迟响应并保留语调和说话风格等声学背景。
WebRTC(网络实时通信)
它是一种公共标准协议,无需额外的插件即可实现浏览器之间的实时双向通信。由于它使用点对点连接并且不涉及中间服务器,因此与 HLS 和 MPEG-DASH 等其他流媒体方法相比,它可以实现最低的延迟。
信令通道
指在建立 WebRTC 连接之前,对等方用于交换连接条件(媒体规范、网络路由候选等)的通信通道。 Kinesis Video Streams WebRTC 将此作为托管服务提供。
SDP(会话描述协议)/ICE(交互式连接建立)
SDP 是描述连接条件(编解码器、分辨率、加密方法等)的标准格式。 ICE是指通过测试包括NAT穿越在内的网络候选路由来建立最佳连接路径的机制。
击晕/转身
STUN 是一种用于确定自己的全球 IP 地址的协议。 TURN 是指在无法直接连接时通过中继服务器建立通信的机制。两者都是用来穿越NAT的。
DTLS(数据报传输层安全)/SRTP(安全实时传输协议)
DTLS 是一种通过 UDP 加密通信的协议。 SRTP是一种加密和传输实时音频和视频数据的标准。 WebRTC将两者结合起来,保证媒体通信的安全。
自适应比特率 (ABR)/前向纠错 (FEC)/抖动缓冲器
ABR是一种根据线路状况动态改变传输比特率的机制。 FEC是指在发送端添加冗余数据并在接收端补偿丢包的技术。抖动缓冲器是一种吸收到达间隔变化并保持流畅播放的机制。
VAD(Voice Activity Detection、音声活动検出)
这项技术仅从音频信号中提取人说话的部分。通过排除静音和噪声部分,有助于提高识别精度并降低处理成本。本文使用Python的WebRTCVAD库(基于高斯混合模型)。
RAG(检索增强生成)
在生成答案时,这是AI从外部知识库中搜索并获取相关信息并根据该信息生成响应的方法。无需重新训练AI模型本身即可反映最新信息和独特数据。
MCP(模型上下文协议)
它是一个用于将人工智能模型与外部工具和数据源连接的开放协议。 Anthropic 于 2024 年发布了它,目前正在跨行业采用。
股线代理
它是AWS提供的用于构建AI代理的开源SDK。您可以构建结合多种工具和语言模型的代理类型工作流程。
MQTT
它是一种轻量级消息传递协议,广泛用于物联网设备之间的通信。它使用一个系统,其中设备通过称为“主题”的标识符发布和订阅信息。
爱尔特克
它是一个用于在 Python 中实现 WebRTC 功能的开源库。它提供了 WebRTC 的主要功能,例如 SDP 交换、DTLS、SCTP、SRTP 和对等互连。
HTTP/2 双向流
是指利用HTTP/2的复用功能,允许客户端和服务器通过单个连接同时、连续地发送和接收数据的通信方法。 Nova Sonic的API就使用这种方法。
[参考链接]
(外部)
AWS 提供的基本模型组“Amazon Nova”的综合页面。发布了每个型号的概述和价格信息。
(外部)
介绍语音转语音模型“Amazon Nova 2 Sonic”的功能、支持的语言和用例的官方页面。
(外部)
托管服务页面,允许您以集成方式使用包括 Nova Sonic 在内的 AWS 基础设施模型。
(外部)
为开发人员提供的综合文档,包括创建信令通道的过程以及如何使用 SDK。
(外部)
可以基于 MQTT 连接和管理数十亿 IoT 设备的托管服务的官方页面。
(外部)
完全托管的服务页面实现RAG。内部文档可以合并到底层模型中。
股线代理(GitHub)(外部)
由 AWS 发布的用于构建 AI 代理的开源 SDK 存储库。提供实施模板。
aiortc(GitHub)(外部)
用于在 Python 中实现 WebRTC 的代表性开源库的存储库。
py-webrtcvad(GitHub)(外部)
使用源自 Python 的 Google WebRTC 项目的 VAD 引擎进行绑定。
模型上下文协议(官网)(外部)
MCP官方网站,用于连接AI模型与外部工具和数据源的开放协议。
[参考文章]
(外部)
官方公告文章宣布 Nova 2 Sonic 现已在美国东部、美国西部和东京地区全面上市。
(外部)
第一款 Nova Sonic 的公告文章。它解释了集成模型解决的传统管道的问题。
(外部)
官方文档涵盖 Nova Sonic 的技术规范,包括双向流 API、RAG 集成和函数调用。
(外部)
架构规范说明,包括一对多信令通道模型和最多 10 个查看器连接。
(外部)
组织 Nova 2 Sonic 功能的文档,例如低延迟多轮对话、多语言支持、多语言语音等。
(外部)
官方文档,描述了实施所需的数值规格,例如输入 16,000Hz、输出 24,000Hz、连接限制 8 分钟。
(外部)
解释具有 WSS 加密信令以及 STUN、TURN 和 ICE 功能的托管服务的工作原理。
[编者后记]
在过去的几年里,“与机器对话”的体验变得异常自然。随着这里介绍的技术变得更加广泛,在我们的生活中哪些情况下我们将有更多机会与对话式AI互动?在车里、在厨房、在工作或在旅行时 - 响应速度和您想要的语言将根据具体情况而有所不同。
在什么情况下你会觉得与机器交谈很舒服?另一方面,在哪些方面您觉得自己真正想与人交谈?如果您不介意,请尝试用语言表达您的感受。我认为技术的未来将由我们每个使用技术的人的感受来塑造。